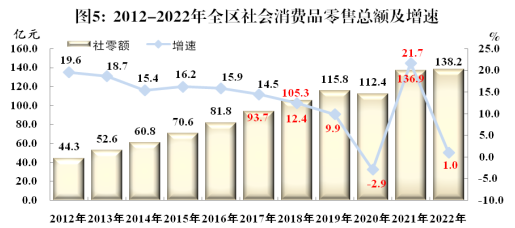
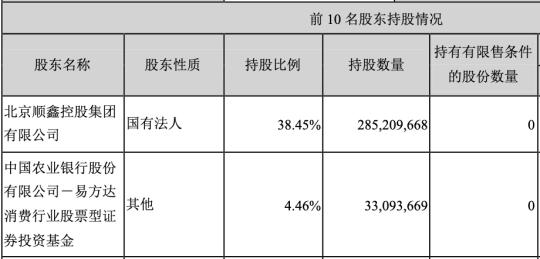
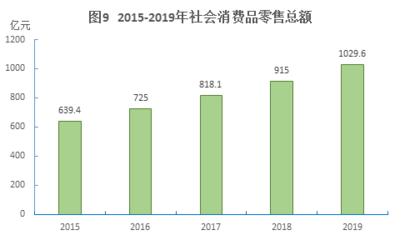
梅州平遠稅務 精準服務助力針紡織品銷售新辦企業揚帆起航

隨著市場環境的不斷優化和創業熱情的持續高漲,梅州平遠縣涌現出一批批充滿活力的新辦企業。其中,針紡織品銷售行業作為連接生產與消費、兼具傳統與時尚的重要領域,正成為當地經濟發展的新生力量。平遠縣稅務局深刻認識到服務好新辦企業對于培育稅源、優化營商環境、促進地方經濟高質量發展的重要意義,特別是針對針紡織品銷售這類市場主體,主動靠前,用心用情,推出了一系列精準化、人性化的服務舉措,全力為新辦企業保駕護航,助力其在市場大潮中穩健啟航、破浪前行。
平遠稅務部門首先在“入門”服務上做足文章。針對新辦針紡織品銷售企業法人往往對稅務登記、票種核定、申報流程等涉稅事項不熟悉的情況,專門設立了“新辦企業服務綠色通道”和“首席稅務服務官”制度。稅務人員主動對接,提供“一站式”輔導,從“電子稅務局”注冊使用、增值稅及企業所得稅政策簡介,到發票申領開具操作演示,進行手把手教學、面對面答疑,確保企業“進門”就能清晰了解涉稅義務與權利,快速完成初期涉稅業務辦理,為企業順利開展經營掃清障礙。
政策精準推送與輔導是平遠稅務服務的又一亮點。針紡織品銷售企業可能涉及小微企業普惠性稅收減免、增值稅征收率優惠、支持創業就業等多種稅收政策。平遠稅務依托稅收大數據,結合行業特點和企業生命周期,通過稅企互動平臺、微信公眾號、網格化服務群等渠道,開展“標簽化”政策推送。不僅及時傳遞最新稅費優惠政策文件,更注重解讀政策要點、享受條件和辦理流程,特別是針對銷售額度的判斷、成本費用的核算等實務問題,開展專題線上講座或小型線下沙龍,確保政策紅利能夠精準“滴灌”到企業,切實減輕企業初創期的資金壓力。
優化辦稅體驗,提升服務質效,平遠稅務始終在路上。大力推廣“非接觸式”辦稅,引導針紡織品銷售企業通過電子稅務局、手機APP辦理常見涉稅業務,實現“多走網路、少跑馬路”。針對該行業可能存在的季節性銷售波動、發票用量臨時性增大等需求,提供發票增版增量“快速響應”機制。辦稅服務廳還提供預約服務、延時服務、容缺辦理等便民措施,最大限度節約企業的辦稅時間成本,讓企業能夠將更多精力投入到市場開拓與經營管理中。
平遠稅務還注重拓展服務的深度與廣度,充當企業發展的“參謀助手”。稅務干部在走訪調研中,不僅了解企業的納稅情況,更關心其經營狀況、市場前景和面臨的困難。結合針紡織品行業趨勢,為企業分析上下游產業鏈情況,提示涉稅風險點,如購銷合同的稅務審查、成本票據的規范管理等,幫助企業規范財務稅務管理,筑牢健康發展基礎。這種“管家式”的貼心服務,讓新辦企業感受到了稅務部門的溫度與擔當。
用心用情,潤物無聲。平遠縣稅務局通過一系列扎實有效的服務舉措,正有力推動著包括針紡織品銷售在內的各類新辦企業輕裝上陣、茁壯成長。優質高效的稅收營商環境,如同肥沃的土壤和溫暖的陽光,滋養著創業的種子,助力企業在平遠這片熱土上扎根生長、揚帆遠航,為區域經濟高質量發展注入源源不斷的稅務動能。
如若轉載,請注明出處:http://m.isoapp.cn/product/48.html
更新時間:2026-05-12 01:57:08