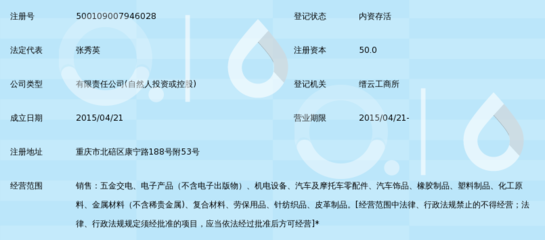
紹興旺進(jìn)針紡織品 素色與超細(xì)搖粒絨面料現(xiàn)貨批發(fā),品質(zhì)與價(jià)格的雙重保障

在針織面料的廣闊市場(chǎng)中,搖粒絨以其獨(dú)特的柔軟手感、優(yōu)異的保暖性能和豐富的應(yīng)用場(chǎng)景,始終占據(jù)著一席之地。而來(lái)自紡織重鎮(zhèn)紹興的旺進(jìn)針紡織品有限公司,正是這一領(lǐng)域的專業(yè)供應(yīng)商之一,專注于提供高品質(zhì)的素色搖粒絨與超細(xì)搖粒絨面料,并以現(xiàn)貨批發(fā)的模式,服務(wù)于廣大下游廠商。
核心產(chǎn)品:素色搖粒絨與超細(xì)搖粒絨
1. 素色搖粒絨:
這是搖粒絨家族中的經(jīng)典品類。紹興旺進(jìn)提供的素色搖粒絨,顏色純正、均勻,覆蓋從基礎(chǔ)黑、白、灰到各類時(shí)尚色彩的廣泛色譜。面料經(jīng)過(guò)起絨工藝處理,表面形成密集、飽滿且不易掉毛的絨粒,觸感蓬松柔軟。其不僅保暖性出色,而且具備良好的透氣性與彈性,是制作秋冬休閑外套、童裝、家居服、毛毯、抱枕以及寵物用品的理想面料。廠家對(duì)色牢度、抗起球性等關(guān)鍵指標(biāo)有嚴(yán)格把控,確保成品品質(zhì)穩(wěn)定。
2. 超細(xì)搖粒絨:
代表了更高階的工藝與品質(zhì)。采用超細(xì)纖維為原料織造,使得面料的絨粒更加細(xì)膩、密度更高。其手感相較于普通搖粒絨更為順滑、輕盈,近乎于天鵝絨般的親膚體驗(yàn),同時(shí)保暖性能有增無(wú)減。超細(xì)搖粒絨的光澤度也更佳,制成的服裝顯得更高檔、有質(zhì)感。它非常適合用于對(duì)舒適度和外觀要求更高的中高端品牌服裝、輕便羽絨服內(nèi)膽、高品質(zhì)家居用品及創(chuàng)意禮品等領(lǐng)域。
廠家優(yōu)勢(shì):紹興旺進(jìn)針紡織品有限公司
坐落于中國(guó)著名的紡織品集散地——紹興,旺進(jìn)針紡充分利用了本地完善的產(chǎn)業(yè)鏈優(yōu)勢(shì)。廠家集研發(fā)、生產(chǎn)、銷售于一體,擁有成熟的生產(chǎn)線和嚴(yán)格的質(zhì)量檢測(cè)體系。其核心優(yōu)勢(shì)在于:
- 源頭廠家,價(jià)格競(jìng)爭(zhēng)力強(qiáng):作為生產(chǎn)廠家直接進(jìn)行批發(fā)銷售,減少了中間流通環(huán)節(jié),能夠?yàn)榭蛻籼峁O具市場(chǎng)競(jìng)爭(zhēng)力的出廠價(jià)格,特別適合批量采購(gòu)的服裝廠、貿(mào)易商及電商客戶。
- 現(xiàn)貨供應(yīng),響應(yīng)速度快:主打“現(xiàn)貨批發(fā)”模式,常備大量素色及超細(xì)搖粒絨庫(kù)存,顏色、克重選擇多樣。這能極大縮短客戶的交貨周期,幫助客戶快速響應(yīng)市場(chǎng)變化,抓住銷售機(jī)遇。
- 品質(zhì)穩(wěn)定,支持定制:在提供標(biāo)準(zhǔn)現(xiàn)貨的廠家也支持根據(jù)客戶的具體要求進(jìn)行定制,如特殊顏色、特定克重、幅寬或功能性處理(如防水、防靜電等),靈活滿足不同項(xiàng)目的需求。
- 樣品與圖片服務(wù):對(duì)于潛在客戶,廠家通常可提供面料樣品冊(cè)或寄送小樣,讓客戶能夠?qū)嵉馗惺苊媪系馁|(zhì)感與色澤。在線上溝通時(shí),清晰、多角度的產(chǎn)品圖片也是了解產(chǎn)品外觀的重要手段。
采購(gòu)與應(yīng)用建議
對(duì)于有意向的采購(gòu)商,建議:
- 明確需求:首先確定所需面料的類型(普通素色或超細(xì))、主要用途、顏色、克重(每平方米的重量,直接影響厚度和保暖度)以及預(yù)計(jì)采購(gòu)量。
- 索取樣品:在批量下單前,務(wù)必索取實(shí)物樣品進(jìn)行檢驗(yàn)和測(cè)試,包括手感、色差、厚度、拉伸及洗滌后的變化等,這是確保面料符合成品要求的關(guān)鍵步驟。
- 溝通細(xì)節(jié):與廠家銷售人員詳細(xì)溝通價(jià)格(通常按米或公斤計(jì))、最小起訂量、付款方式、交貨時(shí)間及物流安排。清晰的溝通有助于建立長(zhǎng)期穩(wěn)定的合作關(guān)系。
###
總而言之,紹興旺進(jìn)針紡織品有限公司憑借其在地域、生產(chǎn)和供應(yīng)模式上的優(yōu)勢(shì),為市場(chǎng)提供了可靠且高性價(jià)比的素色及超細(xì)搖粒絨面料解決方案。無(wú)論是追求經(jīng)典實(shí)用的素色系列,還是青睞高端細(xì)膩的超細(xì)品類,尋求現(xiàn)貨快速支持的批發(fā)客戶都能在此找到合適的選擇。在競(jìng)爭(zhēng)激烈的紡織品市場(chǎng),這樣的源頭廠家無(wú)疑是下游企業(yè)穩(wěn)固供應(yīng)鏈、提升產(chǎn)品競(jìng)爭(zhēng)力的重要合作伙伴。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.isoapp.cn/product/74.html
更新時(shí)間:2026-05-16 19:07:13